前言
此系列文章会详细解读NIO的功能逐步丰满的路程,为Reactor-Netty 库的讲解铺平道路。
关于Java编程方法论-Reactor与Webflux的视频分享,已经完成了Rxjava 与 Reactor,b站地址如下:
Rxjava源码解读与分享:https://www.bilibili.com/video/av34537840
Reactor源码解读与分享:https://www.bilibili.com/video/av35326911
本系列源码解读基于JDK11 api细节可能与其他版本有所差别,请自行解决jdk版本问题。
本系列前几篇:
BIO到NIO源码的一些事儿之NIO 下 之 Selector
Buffer
在Java BIO中,通过BIO到NIO源码的一些事儿之BIO开篇的Demo可知,所有的读写API,都是直接使用byte数组作为缓冲区的,简单直接。我们来拿一个杯子做例子,我们不讲它的材质,只说它的使用属性,一个杯子在使用过程中会首先看其最大容量,然后加水,这里给一个限制,即加到杯子中的水量为杯子最大容量的一半,然后喝水,我们最多也只能喝杯子里所盛水量。由这个例子,我们思考下,杯子是不是可以看作是一个缓冲区,对于杯子倒水的节奏我们是不是可以轻易的控制,从而带来诸多方便,那是不是可以将之前BIO中的缓冲区也加入一些特性,使之变的和我们使用杯子一样便捷。
于是,我们给buffer添加几个属性,对比杯子的最大容量,我们设计添加一个capacity属性,对比加上的容量限制,我们设计添加一个limit属性,对于加水加到杯中的当前位置,我们设计添加一个position属性,有时候我们还想在杯子上自己做个标记,比如喝茶,我自己的习惯就是喝到杯里剩三分之一水的时候再加水加到一半,针对这个情况,设计添加一个mark属性。由此,我们来总结下这几个属性的关系,limit不可能比capacity大的,position又不会大于limit,mark可以理解为一个标签,其也不会大于position,也就是mark <= position <= limit <= capacity。
结合以上概念,我们来对buffer中这几个属性使用时的行为进行下描述:
capacity
也就是缓冲区的容量大小。我们只能往里面写
capacity个byte、long、char等类型。一旦Buffer满了,需要将其清空(通过读数据或者清除数据)才能继续写数据往里写数据。position
(1)当我们写数据到
Buffer中时,position表示当前的位置。初始的position值为0.当一个byte、long、char等数据写到Buffer后,position会向前移动到下一个可插入数据的Buffer位置。position最大可为capacity – 1。(2)当读取数据时,也是从某个特定位置读。当将
Buffer从写模式切换到读模式,position会被重置为0. 当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。limit
(1)在写模式下,
Buffer的limit表示你最多能往Buffer里写多少数据。 写模式下,limit等于Buffer的capacity。(2)读模式时,
limit表示你最多能读到多少数据。因此,当切换Buffer到读模式时,limit会被设置成写模式下的position值。换句话说,你能读到之前写入的所有数据(limit被设置成已写数据的数量,这个值在写模式下就是position)mark
类似于喝茶喝到剩余三分之一谁加水一样,当buffer调用它的reset方法时,当前的位置
position会指向mark所在位置,同样,这个也根据个人喜好,有些人就喜欢将水喝完再添加的,所以mark不一定总会被设定,但当它被设定值之后,那设定的这个值不能为负数,同时也不能大于position。还有一种情况,就是我喝水喝不下了,在最后将水一口喝完,则对照的此处的话,即如果对mark设定了值(并非初始值-1),则在将position或limit调整为小于mark的值的时候将mark丢弃掉。如果并未对mark重新设定值(即还是初始值-1),那么在调用reset方法会抛出InvalidMarkException异常。
可见,经过包装的Buffer是Java NIO中对于缓冲区的抽象。在Java有8中基本类型:byte、short、int、long、float、double、char、boolean,除了boolean类型外,其他的类型都有对应的Buffer具体实现,可见,Buffer是一个用于存储特定基本数据类型的容器。再加上数据时有序存储的,而且Buffer有大小限制,所以,Buffer可以说是特定基本数据类型的线性存储有限的序列。
接着,我们通过下面这幅图来展示下上面几个属性的关系,方便大家更好理解: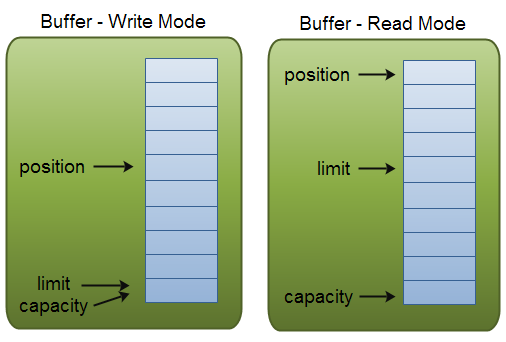
Buffer的基本用法
先来看一个Demo:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
//create buffer with capacity of 48 bytes
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf); //read into buffer.
while (bytesRead != -1) {
buf.flip(); //make buffer ready for read
while(buf.hasRemaining()){
System.out.print((char) buf.get()); // read 1 byte at a time
}
buf.clear(); //make buffer ready for writing
bytesRead = inChannel.read(buf);
}
aFile.close();
我们抛去前两行,来总结下buffer的使用步骤:
- 通过相应类型Buffer的allocate的静态方法来分配指定类型大小的缓冲数据区域(此处为buf);
- 写入数据到Buffer;
- 调用flip()方法:Buffer从写模式切换到读模式;
- 从buffer读取数据;
- 调用clear()方法或则compact()方法。
Buffer分配
那我们依据上面的步骤来一一看下其相应源码实现,这里我们使用ByteBuffer来解读。首先是Buffer分配。1
2
3
4
5
6
7
8
9
10//java.nio.ByteBuffer#allocate
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw createCapacityException(capacity);
return new HeapByteBuffer(capacity, capacity);
}
//java.nio.ByteBuffer#allocateDirect
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
ByteBuffer是一个抽象类,具体的实现有HeapByteBuffer和DirectByteBuffer。分别对应Java堆缓冲区与堆外内存缓冲区。Java堆缓冲区本质上就是byte数组(由之前分析的,我们只是在字节数组上面加点属性,辅以逻辑,实现一些更复杂的功能),所以实现会比较简单。而堆外内存涉及到JNI代码实现,较为复杂,所以我们先来分析HeapByteBuffer的相关操作,随后再专门分析DirectByteBuffer。
我们来看HeapByteBuffer相关构造器源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32//java.nio.HeapByteBuffer#HeapByteBuffer(int, int)
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
this.address = ARRAY_BASE_OFFSET;
}
//java.nio.ByteBuffer#ByteBuffer(int, int, int, int, byte[], int)
ByteBuffer(int mark, int pos, int lim, int cap,
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
//java.nio.Buffer#Buffer
Buffer(int mark, int pos, int lim, int cap) {
if (cap < 0)
throw createCapacityException(cap);
this.capacity = cap;
limit(lim);
position(pos);
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
由上,HeapByteBuffer通过初始化字节数组hd,在虚拟机堆上申请内存空间。
因在ByteBuffer中定义有hb这个字段,它是一个byte[]类型,为了获取这个字段相对于当前这个ByteBuffer对象所在内存地址,通过private static final long ARRAY_BASE_OFFSET = UNSAFE.arrayBaseOffset(byte[].class)中这个UNSAFE操作来获取这个数组第一个元素位置与该对象所在地址的相对长度,这个对象的地址代表你的头所在的位置,将这个数组看作你的鼻子,而这里返回的是你的鼻子距离头位置的那个长度,即数组第一个位置距离这个对象开始地址所在位置,这个是在class字节码加载到jvm里的时候就已经确定了。
如果ARRAY_INDEX_SCALE = UNSAFE.arrayIndexScale(byte[].class)为返回非零值,则可以使用该比例因子以及此基本偏移量(ARRAY_BASE_OFFSET)来形成新的偏移量,以访问这个类的数组元素。知道这些,在ByteBuffer的slice duplicate之类的方法,就能理解其操作了,就是计算数组中每一个元素所占空间长度得到ARRAY_INDEX_SCALE,然后当我确定我从数组第5个位置作为该数组的开始位置操作时,我就可以使用this.address = ARRAY_BASE_OFFSET + off * ARRAY_INDEX_SCALE。
我们再通过下面的源码对上述内容对比消化下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45//java.nio.HeapByteBuffer
protected HeapByteBuffer(byte[] buf,
int mark, int pos, int lim, int cap,
int off)
{
super(mark, pos, lim, cap, buf, off);
/*
hb = buf;
offset = off;
*/
this.address = ARRAY_BASE_OFFSET + off * ARRAY_INDEX_SCALE;
}
public ByteBuffer slice() {
return new HeapByteBuffer(hb,
-1,
0,
this.remaining(),
this.remaining(),
this.position() + offset);
}
ByteBuffer slice(int pos, int lim) {
assert (pos >= 0);
assert (pos <= lim);
int rem = lim - pos;
return new HeapByteBuffer(hb,
-1,
0,
rem,
rem,
pos + offset);
}
public ByteBuffer duplicate() {
return new HeapByteBuffer(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
Buffer的读写
每个buffer都是可读的,但不是每个buffer都是可写的。这里,当buffer有内容变动的时候,会首先调用buffer的isReadOnly判断此buffer是否只读,只读buffer是不允许更改其内容的,但mark、position 和 limit的值是可变的,这是我们人为给其额外的定义,方便我们增加功能逻辑的。当在只读buffer上调用修改时,则会抛出ReadOnlyBufferException异常。我们来看buffer的put方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//java.nio.ByteBuffer#put(java.nio.ByteBuffer)
public ByteBuffer put(ByteBuffer src) {
if (src == this)
throw createSameBufferException();
if (isReadOnly())
throw new ReadOnlyBufferException();
int n = src.remaining();
if (n > remaining())
throw new BufferOverflowException();
for (int i = 0; i < n; i++)
put(src.get());
return this;
}
//java.nio.Buffer#remaining
public final int remaining() {
return limit - position;
}
上面remaining方法表示还剩多少数据未读,上面的源码讲的是,如果src这个ByteBuffer的src.remaining()的数量大于要存放的目标Buffer的还剩的空间,直接抛溢出的异常。然后通过一个for循环,将src剩余的数据,依次写入目标Buffer中。接下来,我们通过src.get()来探索下Buffer的读操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//java.nio.HeapByteBuffer#get()
public byte get() {
return hb[ix(nextGetIndex())];
}
public byte get(int i) {
return hb[ix(checkIndex(i))];
}
//java.nio.HeapByteBuffer#ix
protected int ix(int i) {
return i + offset;
}
//java.nio.Buffer#nextGetIndex()
final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
这里,为了依次读取数组中的数据,这里使用nextGetIndex()来获取要读位置,即先返回当前要获取的位置值,然后position自己再加1。以此在前面ByteBuffer#put(java.nio.ByteBuffer)所示源码中的for循环中依次对剩余数据的读取。上述get(int i)不过是从指定位置获取数据,实现也比较简单HeapByteBuffer#ix也只是确定所要获取此数组对象指定位置数据,其中的offset表示第一个可读字节在该字节数组中的位置(就好比我喝茶杯底三分之一水是不喝的,每次都从三分之一水量开始位置计算喝了多少或者加入多少水)。
接下来看下单个字节存储到指定字节数组的操作,与获取字节数组单个位置数据相对应,代码比较简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//java.nio.HeapByteBuffer#put(byte)
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
public ByteBuffer put(int i, byte x) {
hb[ix(checkIndex(i))] = x;
return this;
}
//java.nio.Buffer#nextPutIndex()
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
前面的都是单个字节的,下面来讲下批量操作字节数组是如何进行的,因过程知识点重复,这里只讲get,先看源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//java.nio.ByteBuffer#get(byte[])
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
//java.nio.ByteBuffer#get(byte[], int, int)
public ByteBuffer get(byte[] dst, int offset, int length) {
// 检查参数是否越界
checkBounds(offset, length, dst.length);
// 检查要获取的长度是否大于Buffer中剩余的数据长度
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
for (int i = offset; i < end; i++)
dst[i] = get();
return this;
}
//java.nio.Buffer#checkBounds
static void checkBounds(int off, int len, int size) { // package-private
if ((off | len | (off + len) | (size - (off + len))) < 0)
throw new IndexOutOfBoundsException();
}
通过这个方法将这个buffer中的字节数据读到我们给定的目标数组dst中,由checkBounds可知,当要写入目标字节数组的可写长度小于将要写入数据的长度的时候,会产生边界异常。当要获取的长度是大于Buffer中剩余的数据长度时抛出BufferUnderflowException异常,当验证通过后,接着就从目标数组的offset位置开始,从buffer获取并写入offset + length长度的数据。
可以看出,HeapByteBuffer是封装了对byte数组的简单操作。对缓冲区的写入和读取本质上是对数组的写入和读取。使用HeapByteBuffer的好处是我们不用做各种参数校验,也不需要另外维护数组当前读写位置的变量了。
同时我们可以看到,Buffer中对position的操作没有使用锁保护,所以Buffer不是线程安全的。如果我们操作的这个buffer会有多个线程使用,则针对该buffer的访问应通过适当的同步控制机制来进行保护。
ByteBuffer的模式
jdk本身是没这个说法的,只是按照我们自己的操作习惯,我们将Buffer分为两种工作模式,一种是接收数据模式,一种是输出数据模式。我们可以通过Buffer提供的flip等操作来切换Buffer的工作模式。
我们来新建一个容量为10的ByteBuffer:1
ByteBuffer.allocate(10);
由前面所学的HeapByteBuffer的构造器中的相关代码可知,这里的position被设置为0,而且 capacity和limit设置为 10,mark设置为-1,offset设定为0。
可参考下图展示:
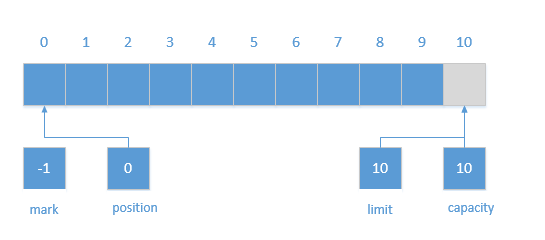
新建的Buffer处于接收数据的模式,可以向Buffer放入数据,在放入一个对应基本类型的数据后(此处假如放入一个char类型数据),position加一,参考我们上面所示源码,如果position已经等于limit了还进行put操作,则会抛出BufferOverflowException异常。
我们向所操作的buffer中put 5个char类型的数据进去:1
buffer.put((byte)'a').put((byte)'b').put((byte)'c').put((byte)'d').put((byte)'e');
会得到如下结果视图:
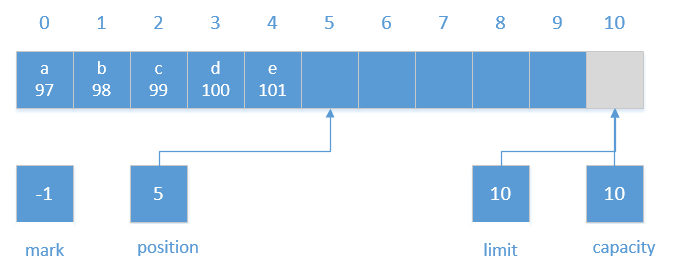
由之前源码分析可知,Buffer的读写的位置变量都是基于position来做的,其他的变量都是围绕着它进行辅助管理的,所以如果从Buffer中读取数据,要将Buffer切换到输出数据模式(也就是读模式)。此时,我们就可以使用Buffer提供了flip方法。1
2
3
4
5
6
7//java.nio.Buffer#flip
public Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
我们知道,在put的时候,会进行java.nio.Buffer#nextPutIndex()的调用,里面会进行position >= limit,所以,此时再进行写操作的话,会从第0个位置开始进行覆盖,而且只能写到flip操作之后limit的位置。1
2
3
4
5
6//java.nio.Buffer#nextPutIndex()
final int nextPutIndex() { // package-private
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
在做完put操作后,position会自增一下,所以,flip操作示意图如下:
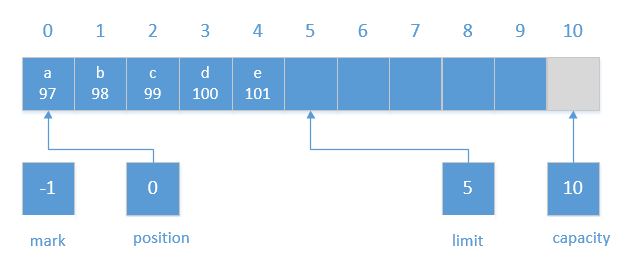
也是因为position为0了,所以我们可以很方便的从Buffer中第0个位置开始读取数据,不需要别的附加操作。由之前解读可知,每次读取一个元素,position就会加一,如果position已经等于limit还进行读取,则会抛出BufferUnderflowException异常。
我们通过flip方法把Buffer从接收写模式切换到输出读模式,如果要从输出模式切换到接收模式,可以使用compact或者clear方法,如果数据已经读取完毕或者数据不要了,使用clear方法,如果只想从缓冲区中释放一部分数据,而不是全部(即释放已读数据,保留未读数据),然后重新填充,使用compact方法。
对于clear方法,我们先来看它的源码:1
2
3
4
5
6
7//java.nio.Buffer#clear
public Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
我们可以看到,它的clear方法内并没有做清理工作,只是修改位置变量,重置为初始化时的状态,等待下一次将数据写入缓冲数组。
接着,来看compact操作的源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39//java.nio.HeapByteBuffer#compact
public ByteBuffer compact() {
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
position(remaining());
limit(capacity());
discardMark();
return this;
}
//java.nio.ByteBuffer#position
ByteBuffer position(int newPosition) {
super.position(newPosition);
return this;
}
//java.nio.Buffer#position(int)
public Buffer position(int newPosition) {
if (newPosition > limit | newPosition < 0)
throw createPositionException(newPosition);
position = newPosition;
if (mark > position) mark = -1;
return this;
}
//java.nio.ByteBuffer#limit
ByteBuffer limit(int newLimit) {
super.limit(newLimit);
return this;
}
//java.nio.Buffer#limit(int)
public Buffer limit(int newLimit) {
if (newLimit > capacity | newLimit < 0)
throw createLimitException(newLimit);
limit = newLimit;
if (position > limit) position = limit;
if (mark > limit) mark = -1;
return this;
}
//java.nio.Buffer#discardMark
final void discardMark() {
mark = -1;
}
这里使用了数组的拷贝操作,将未读元素转移到该字节数组从0开始的位置,由于remaining()返回的是limit - position,假如在flip操作的时候填入的元素有5个,那么limit为5,此时读到了第三个元素,也就是在调用compact时position的数值为2,那remaining()的值就为3,也就是此时position为3,compact操作后,limit会回归到和初始化数组容量大小一样,并将mark值置为 -1。
我们来看示意图,在进行buffer.compact()调用前:
%E8%B0%83%E7%94%A8%E5%89%8D.png?raw=true)
buffer.compact()调用后:
%E8%B0%83%E7%94%A8%E5%90%8E.png?raw=true)
ByteBuffer的其他方法
接下来,我们再接触一些ByteBuffer的其他方法,方便在适当的条件下进行使用。
rewind方法
首先来看它的源码:1
2
3
4
5
6//java.nio.Buffer#rewind
public Buffer rewind() {
position = 0;
mark = -1;
return this;
}
这里就是将position设定为0,mark设定为-1,其他设定的管理属性(capacity,limit)不变。结合前面的知识,在字节数组写入数据后,它的clear方法也只是重置我们在Buffer中设定的那几个增强管理属性(capacity、position、limit、mark),此处的英文表达的意思也很明显:倒带,也就是可以回头重新写,或者重新读。但是我们要注意一个前提,我们要确保已经恰当的设置了limit。这个方法可以在Channel的读或者写之前调用,如:1
2
3out.write(buf); // Write remaining data
buf.rewind(); // Rewind buffer
buf.get(array); // Copy data into array
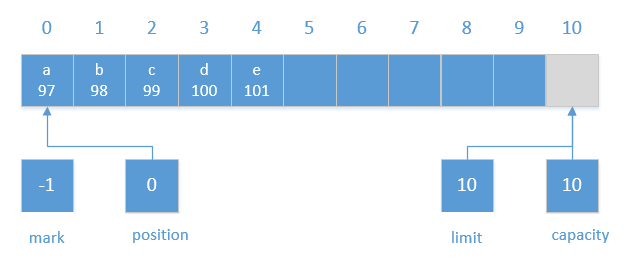
我们通过下图来进行展示执行rewind操作后的结果:
duplicate 方法
在JDK9版本中,新增了这个方法。用来创建一个与原始Buffer一样的新Buffer。新Buffer的内容和原始Buffer一样。改变新Buffer内的数据,同样会体现在原始Buffer上,反之亦然。两个Buffer都拥有自己独立的 position,limit 和mark 属性。
刚创建的新Buffer的position,limit 和mark 属性与原始Buffer对应属性的值相同。
还有一点需要注意的是,如果原始Buffer是只读的(即HeapByteBufferR),那么新Buffer也是只读的。如果原始Buffer是DirectByteBuffer,那新Buffer也是DirectByteBuffer。
我们来看相关源码实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27//java.nio.HeapByteBuffer#duplicate
public ByteBuffer duplicate() {
return new HeapByteBuffer(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
//java.nio.HeapByteBufferR#duplicate
public ByteBuffer duplicate() {
return new HeapByteBufferR(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
//java.nio.DirectByteBuffer#duplicate
public ByteBuffer duplicate() {
return new DirectByteBuffer(this,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
0);
}
基本类型的参数传递都是值传递,所以由上面源码可知每个新缓冲区都拥有自己的 position、limit 和 mark 属性,而且他们的初始值使用了原始Buffer此时的值。
但是,从HeapByteBuffer角度来说,对于hb 作为一个数组对象,属于对象引用传递,即新老Buffer共用了同一个字节数组对象。无论谁操作,都会改变另一个。
从DirectByteBuffer角度来说,直接内存看重的是地址操作,所以,其在创建这个新Buffer的时候传入的是原始Buffer的引用,进而可以获取到相关地址。
asReadOnlyBuffer
可以使用 asReadOnlyBuffer() 方法来生成一个只读的缓冲区。这与duplicate()实现有些相同,除了这个新的缓冲区不允许使用put(),并且其isReadOnly()函数
将会返回true 。 对这一只读缓冲区调用put()操作,会导致ReadOnlyBufferException异常。
我们来看相关源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62//java.nio.ByteBuffer#put(java.nio.ByteBuffer)
public ByteBuffer put(ByteBuffer src) {
if (src == this)
throw createSameBufferException();
if (isReadOnly())
throw new ReadOnlyBufferException();
int n = src.remaining();
if (n > remaining())
throw new BufferOverflowException();
for (int i = 0; i < n; i++)
put(src.get());
return this;
}
//java.nio.HeapByteBuffer#asReadOnlyBuffer
public ByteBuffer asReadOnlyBuffer() {
return new HeapByteBufferR(hb,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
//java.nio.HeapByteBufferR#asReadOnlyBuffer
//HeapByteBufferR下直接调用其duplicate方法即可,其本来就是只读的
public ByteBuffer asReadOnlyBuffer() {
return duplicate();
}
//java.nio.DirectByteBuffer#asReadOnlyBuffer
public ByteBuffer asReadOnlyBuffer() {
return new DirectByteBufferR(this,
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
0);
}
//java.nio.DirectByteBufferR#asReadOnlyBuffer
public ByteBuffer asReadOnlyBuffer() {
return duplicate();
}
//java.nio.HeapByteBufferR#HeapByteBufferR
protected HeapByteBufferR(byte[] buf,
int mark, int pos, int lim, int cap,
int off)
{
super(buf, mark, pos, lim, cap, off);
this.isReadOnly = true;
}
//java.nio.DirectByteBufferR#DirectByteBufferR
DirectByteBufferR(DirectBuffer db,
int mark, int pos, int lim, int cap,
int off)
{
super(db, mark, pos, lim, cap, off);
this.isReadOnly = true;
}
可以看到,ByteBuffer的只读实现,在构造器里首先将isReadOnly属性设定为true。接着,HeapByteBufferR继承了HeapByteBuffer 类(DirectByteBufferR也是类似实现,就不重复了),并重写了所有可对buffer修改的方法。把所有能修改buffer的方法都直接抛出ReadOnlyBufferException来保证只读。来看DirectByteBufferR相关源码,其他对应实现一样:1
2
3
4//java.nio.DirectByteBufferR#put(byte)
public ByteBuffer put(byte x) {
throw new ReadOnlyBufferException();
}
slice 方法
slice从字面意思来看,就是切片,用在这里,就是分割ByteBuffer。即创建一个从原始ByteBuffer的当前位置(position)开始的新ByteBuffer,并且其容量是原始ByteBuffer的剩余消费元素数量( limit-position)。这个新ByteBuffer与原始ByteBuffer共享一段数据元素子序列,也就是设定一个offset值,这样就可以将一个相对数组第三个位置的元素看作是起点元素,此时新ByteBuffer的position就是0,读取的还是所传入这个offset的所在值。分割出来的ByteBuffer也会继承只读和直接属性。
我们来看相关源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//java.nio.HeapByteBuffer#slice()
public ByteBuffer slice() {
return new HeapByteBuffer(hb,
-1,
0,
this.remaining(),
this.remaining(),
this.position() + offset);
}
protected HeapByteBuffer(byte[] buf,
int mark, int pos, int lim, int cap,
int off)
{
super(mark, pos, lim, cap, buf, off);
/*
hb = buf;
offset = off;
*/
this.address = ARRAY_BASE_OFFSET + off * ARRAY_INDEX_SCALE;
}
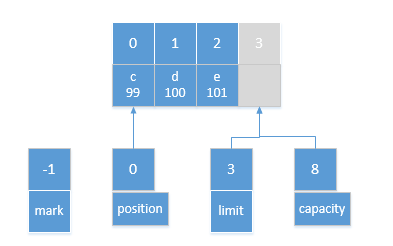
由源码可知,新ByteBuffer和原始ByteBuffer共有了一个数组,新ByteBuffer的mark值为-1,position值为0,limit和capacity都为原始Buffer中limit-position的值。
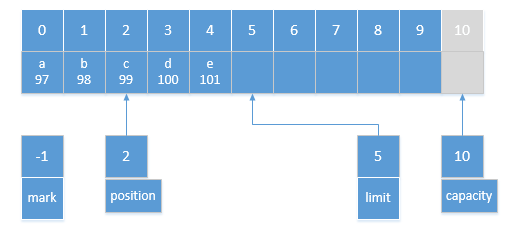
于是,我们可以通过下面两幅图来展示slice方法前后的对比。
原始ByteBuffer:
调用slice方法分割后得到的新ByteBuffer:
本篇到此为止,在下一篇中,我会着重讲下DirectByteBuffer的实现细节。
